
State Space Models

Introduction
State Space Models (SSMs) are an effective architecture for sequence modeling in machine learning. These models differ from traditional machine learning methods due to their approach to handling data sequences. SSMs represent a dynamic system in terms of a set of input, output, and state variables. Their strength lies in their ability to model complex systems by focusing on how these variables evolve over time. This characteristic makes SSMs particularly effective in tasks involving temporal sequences or time series data, where understanding the evolution of data points is crucial. Originally developed for signal processing, SSMs have found applications in various fields, including economics, engineering, and now, machine learning.
The core principle of SSMs involves the concept of state, which is a representation of the information necessary to describe the system at any time. In machine learning, this translates to an ability to represent data sequences without requiring explicit knowledge of all previous data points. SSMs manage this by summarizing past information into a state and using it to predict future states or outputs.
Let’s take a look at a couple SSM architectures.
Mamba: A Shift to Sequence Modeling
Mamba is a state-space model that represents a significant shift from traditional transformer models like GPT-4. Mamba’s architecture, focusing on selective SSMs and a hardware-friendly design, is better able to handle long sequences while ensuring computational efficiency.
Mamba’s architecture is designed to process complex sequences in fields like language processing, genomics, and audio analysis. It uses a selective SSM layer, a departure from models that treat all input data uniformly. This layer allows Mamba to focus on relevant information and adapt to input dynamically. Another hallmark of Mamba is its hardware-aware algorithm. Optimized for modern hardware such as GPUs, Mamba is designed to maximize parallel processing and minimize memory requirements. This design aims for a high level of performance for sequence models.
When compared with transformer models such as GPT-4, Mamba demonstrates several advantages in processing long sequences. Transformer models, although powerful in handling sequences in parallel and featuring a robust attention mechanism, face challenges with longer sequences. Mamba addresses these challenges by employing selective state spaces, which enable faster inference and linear scaling with sequence length. The Mamba block, the building block of the architecture, is designed for ease of implementation, allowing users to efficiently process data and obtain outputs. It combines a H3 (Hungry Hungry Hippos) block with the gated multilayer perceptron (MLP) as follows:
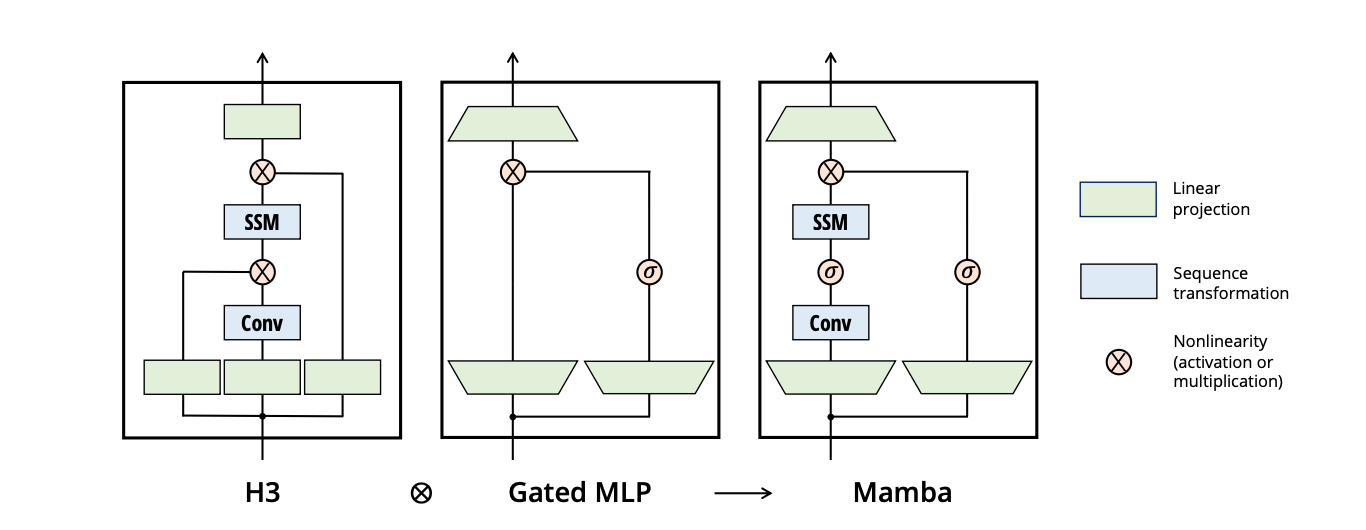
With its ability to efficiently handle lengthy sequences and its high performance, Mamba may play an important role in the development of AI systems, representing a shift towards better performance in sequence modeling.
StripedHyena
StripedHyena presents another approach that diverges from the transformer architecture. StripedHyena offers a new set of architectures aimed at improving training and inference performance. The models are designed to be faster, more memory-efficient, and capable of handling very long contexts of up to 128,000 tokens.
StripedHyena represents a hybrid architecture that combines multi-head, grouped-query attention, and gated convolutions arranged in Hyena blocks. The architecture allows for low latency, faster decoding, and higher throughput than traditional transformers. StripedHyena's design also brings improvements to training and inference-optimal scaling. It is trained on sequences of up to 32k, enabling it to process longer prompts.
StripedHyena has demonstrated good performance in long-context tasks. It is faster than conventional transformers in the end-to-end training of sequences with large numbers of tokens, allowing it to outperform conventional transformers in long-context summarization tasks.
StripedHyena aims to push the boundaries of architectural design, with future explorations planned for larger models, longer contexts, multimodal support, further performance optimizations, and integration into retrieval pipelines to leverage the longer context.
StripedHyena is available as an open-source project, with its repository hosted on GitHub. This accessibility allows for broader usage and experimentation by the AI community, fostering innovation and development in the field of language modeling.
The Future of Language Modeling: SSMs vs Transformers
Language modeling is seeing an evolution with the advent of SSMs challenging the dominance of transformer models. SSMs, particularly through recent developments like the H3 layer, demonstrate promising potential for language modeling.
SSMs are being adapted for language modeling due to their ability to model long-range dependencies. Despite their scalability and efficiency, SSMs had initially lagged behind transformer models in language modeling tasks. However, this gap is closing rapidly. The H3 layer is a significant step in this direction. It replaces almost all attention layers in GPT-style transformers, achieving or even surpassing their quality. Notably, H3 has scaled up to 2.7B parameters and has been tested on the Pile dataset, where it matched or outperformed transformers of similar sizes.
H3 is able to address key challenges faced by SSMs. For instance, H3 can remember tokens over the entire sequence and compare the current token to previous ones, tasks where earlier SSMs struggled. This was demonstrated through synthetic language modeling tasks, where H3's ability to solve these translated into better performance on natural language benchmarks like OpenWebText. Moreover, H3's design involves using shift and diagonal SSMs combined with multiplicative operations against projections of the input, adding to its expressivity and efficiency.
In addition to improvements in model architecture, innovations in training efficiency are also being explored. FlashConv, also proposed in the H3 study, uses a fused block FFT algorithm and a novel state-passing algorithm to improve efficiency on long sequences, allowing SSM-based models like H3 to be trained more efficiently on modern hardware.
These advancements suggest that SSMs are becoming increasingly competitive with transformers in language modeling. The H3 layer is able to match or even outperform transformers on various benchmarks, coupled with its efficiency and scalability. This shift towards more efficient, scalable, and performant models indicates continued improvement in natural language processing.
Practical Applications and Industry Impact
SSMs are increasingly being recognized for their potential in various domains, including language modeling, audio processing, and genomics. These models offer a promising alternative to the more traditional Transformer models, especially in terms of computational efficiency and handling long sequences.
We’ve discussed language modeling above. Let’s briefly discuss audio processing and genomics.
- Audio Processing: In the realm of audio, SSMs have been successfully applied to model complex audio waveforms. A notable example is SaShiMi, an architecture designed for autoregressive waveform modeling. SaShiMi leverages the capabilities of SSMs to capture long-range dependencies in audio data, an area where traditional CNNs and RNNs often struggle. This is particularly significant for applications like speech recognition, music generation, and audio analysis, where capturing the nuances of audio data is crucial.
- Genomics: SSMs, including Mamba, have been applied to genomics. The ability of these models to process long sequences efficiently makes them well-suited for analyzing complex genetic data. The ability to model and analyze long DNA sequences can be critical for understanding genetic patterns, disease prediction, and personalized medicine.
SSMs are both powerful and resource-efficient. If they continue to evolve and improve, we may see their application in fields where the size of datasets was previously a limiting factor. While their application to language models is just beginning, SSMs could also lead to superior solutions in areas like speech recognition, translation, and bioinformatics.