
The AI Reasoning Layer Your Agents Are Missing

There's a comfortable illusion in the modern AI stack. You have an LLM that generates fluent text. A vector store that retrieves relevant documents. An orchestration framework that chains tool calls together. On paper, your agent can do anything.
Then someone asks it a question that requires thinking.
"Who can transitively access the production database?" "What breaks if this supplier goes offline?" "Why did the system flag this transaction — and what's the minimum change to make it compliant?" The agent retrieves some documents, generates a confident answer, and gets it wrong. Not because the model is stupid. Because retrieval is not reasoning, and your stack has no place where reasoning actually happens.
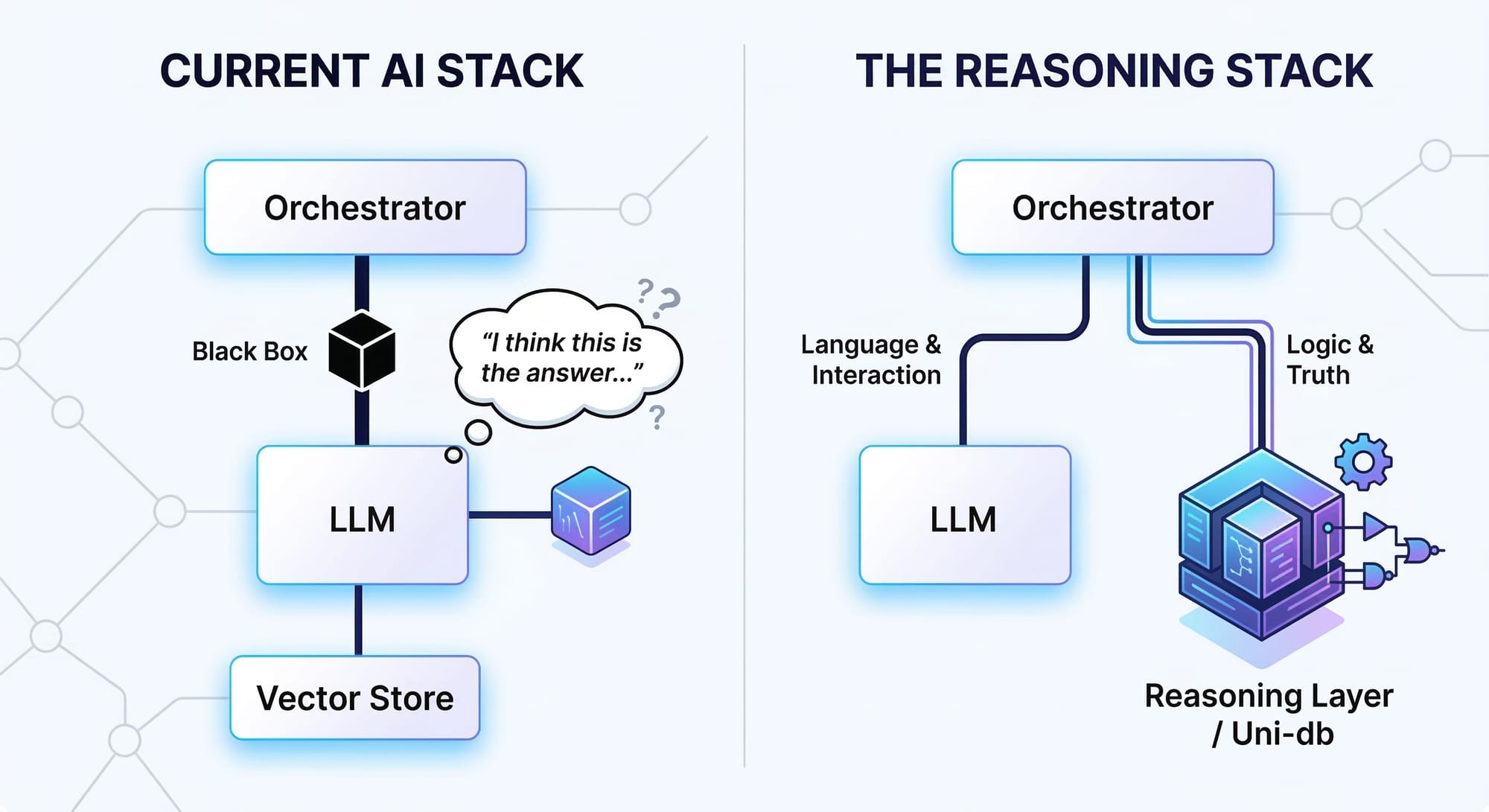
The AI reasoning layer — the missing infrastructure between retrieval and action — is where an agent stores structured knowledge, applies formal rules, and simulates consequences before committing. That layer doesn't exist in most agent architectures. The result is agents that are fluent, confident, and structurally blind.
That gap has a name, a cost, and a fix. This article is our view of the problem and why we built Uni to close it.
What is an AI reasoning layer? The infrastructure between retrieval and action where structured thinking happens. An AI reasoning layer gives agents three capabilities RAG cannot: formal reasoning over declared rules, hypothetical simulation of consequences before acting, and explainable decisions with full derivation traces. Most agent stacks have retrieval and generation but nothing in between — which is why they're fluent and structurally blind.
The Agentic Moment — Why the Missing Layer Is the Bottleneck
The defining shift in AI is not better models. It is agents.
The industry is moving from LLMs as conversational tools to LLMs as autonomous actors — systems that maintain persistent memory, reason over structured knowledge, plan multi-step actions, and explain their decisions. Every major lab is racing toward this. OpenAI, Anthropic, Google, and a hundred startups are building frameworks for agents that act in the world, not just talk about it.
For many enterprise agent use cases, raw model capability is no longer the primary bottleneck. The harder problem is giving models structured state, deterministic reasoning, and safe ways to simulate action. A 2025 study from MIT's Project NANDA on generative AI deployments found that most have yet to move the needle on ROI — and the failure mode is consistent: organizations bolt an LLM onto existing systems and wonder why it can't do what a knowledgeable human would. Gartner predicts over 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs and unclear business value. A Cleanlab survey of 1,837 practitioners found only 5% had agents in production — and of those, only 10% achieved greater than 40% project success. McKinsey's 2025 State of AI survey reports that 51% of organizations deploying AI experienced at least one negative consequence, with inaccuracy the most common. The model has intelligence but no world model, pattern recognition but no structural understanding, fluency but no formal reasoning.
The industry is waking up to this. LeCun's billion-dollar bet on world models for physical AI captures the principle exactly: agents need internal representations of the world they operate in to predict consequences before acting. Richens et al. at Google DeepMind proved formally that any agent capable of generalizing across goal-directed tasks must have learned a predictive model of its environment — world models aren't a nice-to-have, they're mathematically necessary. The same principle applies to enterprise agents in structured domains — permissions, supply chains, regulatory frameworks — where the world model isn't a physics simulator. It's a knowledge graph with formal rules.
Most agent stacks can retrieve context and generate plausible actions, but they still struggle with transitive dependencies, formal policy evaluation, and counterfactual analysis. They cannot simulate consequences before acting — what breaks if we revoke this permission, disable this firewall rule, switch this supplier. And they cannot explain their decisions with auditable proof, only confidence scores and crossed fingers.
The memory is a bag of embeddings. The reasoning is prompt engineering. The planning is hope. A recent analysis put it plainly: current practices for building LLM-powered reasoning tools are ad hoc — and we can do better.
This is the state of most AI agent infrastructure in 2026. For enterprise use cases involving structured knowledge, it's a category error — like trying to build an airplane by making a car go really fast. Speed isn't the problem. The physics is different.
Where Retrieval Is Enough — and Where It Isn't
Before diagnosing what's missing, let's be precise about where the current stack works well.
RAG is genuinely effective for a class of problems. Summarizing long documents, answering questions from a knowledge base, drafting content from reference material, powering customer support with grounded responses — these are retrieval problems, and retrieval-augmented generation handles them. If the answer lives in a document chunk and the question is essentially "find me the relevant passage and rephrase it," RAG delivers.
LLMs are also getting better at multi-step synthesis, decomposition, and tool use. Chain-of-thought prompting can improve performance on reasoning-like tasks. Test-time compute scaling — spending more inference cycles on harder problems — is a genuine frontier, with foundational work showing that optimal test-time compute can outperform scaling model parameters by 14x. These are real advances, not hype.
The problems start when answers depend on structure rather than similarity. MultiHop-RAG benchmarked 2,556 multi-hop queries and found existing RAG methods "perform unsatisfactorily" the moment a question requires evidence chained across multiple documents. KAG showed that RAG systems depend heavily on surface-level text similarity, which often fails to capture deeper logical relationships between pieces of knowledge. As a result, tasks involving calculations, temporal relationships, or analytical reasoning are beyond standard RAG frameworks entirely. When the question involves transitive relationships across a graph, formal rules that must be applied deterministically, hypothetical changes to a world model, or audit-grade explanations that trace every conclusion to its source — that's where retrieval and generation hit a wall. Not because they're bad tools. Because they're the wrong tools.
This article is about that second category: enterprise agents operating in structured, high-stakes domains — permissions, dependencies, regulations, hierarchies, supply chains, infrastructure — where knowledge is constructed from rules and relationships, and where "close enough" isn't close enough.
The Stack That Can't Think
If you squint at a typical agent architecture for these domains, it looks like this: an LLM for generation, a vector store for retrieval, maybe a graph database for relationships, a search index for keywords, a rules engine someone wrote in Python, and several hundred lines of glue code holding it all together. A survey of emerging agent architectures found the pattern is consistent: long-horizon tasks amplify compounding errors, and nondeterminism from sampling and tool variability makes evaluation and debugging difficult without standardized trace protocols. When researchers studied multi-agent LLM systems specifically, they found failure rates of 41–86.7% — because even with 98% per-agent success, chaining agents degrades overall system success to 90% or lower.
Each system is its own island — its own data model, its own consistency boundary, its own deployment overhead. The graph database runs as a separate server process. The vector store runs as another. The rules engine is a bespoke script nobody wants to maintain. Data flows between them through ETL pipelines that break silently.
The agent can't reason across these systems. It queries each one independently, collects the results, and hands them to the LLM with instructions: "Here are the graph relationships. Here are the similar documents. Here are the rules that fired. Now figure out what to do."
The LLM obliges — fluently, confidently, and without any formal guarantee that the answer is consistent with the facts it was given.
This architecture lacks what engineers call mechanical sympathy — the principle that software should be designed for how the underlying system actually works, not how you wish it worked. An agent diagnosing a security incident needs to traverse a relationship chain (what depends on this server?), check semantic relevance (what incidents were similar?), apply domain rules (does this violate our access control policy?), simulate a counterfactual (what if we isolate this subnet?), and explain the whole chain to an auditor. That's one thought. In the current stack, it's five queries to five systems, stitched together by instructions and goodwill.
The result is fragile, unexplainable, and impossible to audit. Not because any individual component is bad. Because the architecture treats cognition as a plumbing problem.
Four Gaps in the AI Reasoning Layer
Strip away the tooling and look at what agents need to think in structured domains. Four gaps define what they're missing.

Gap 1: No Structured Memory
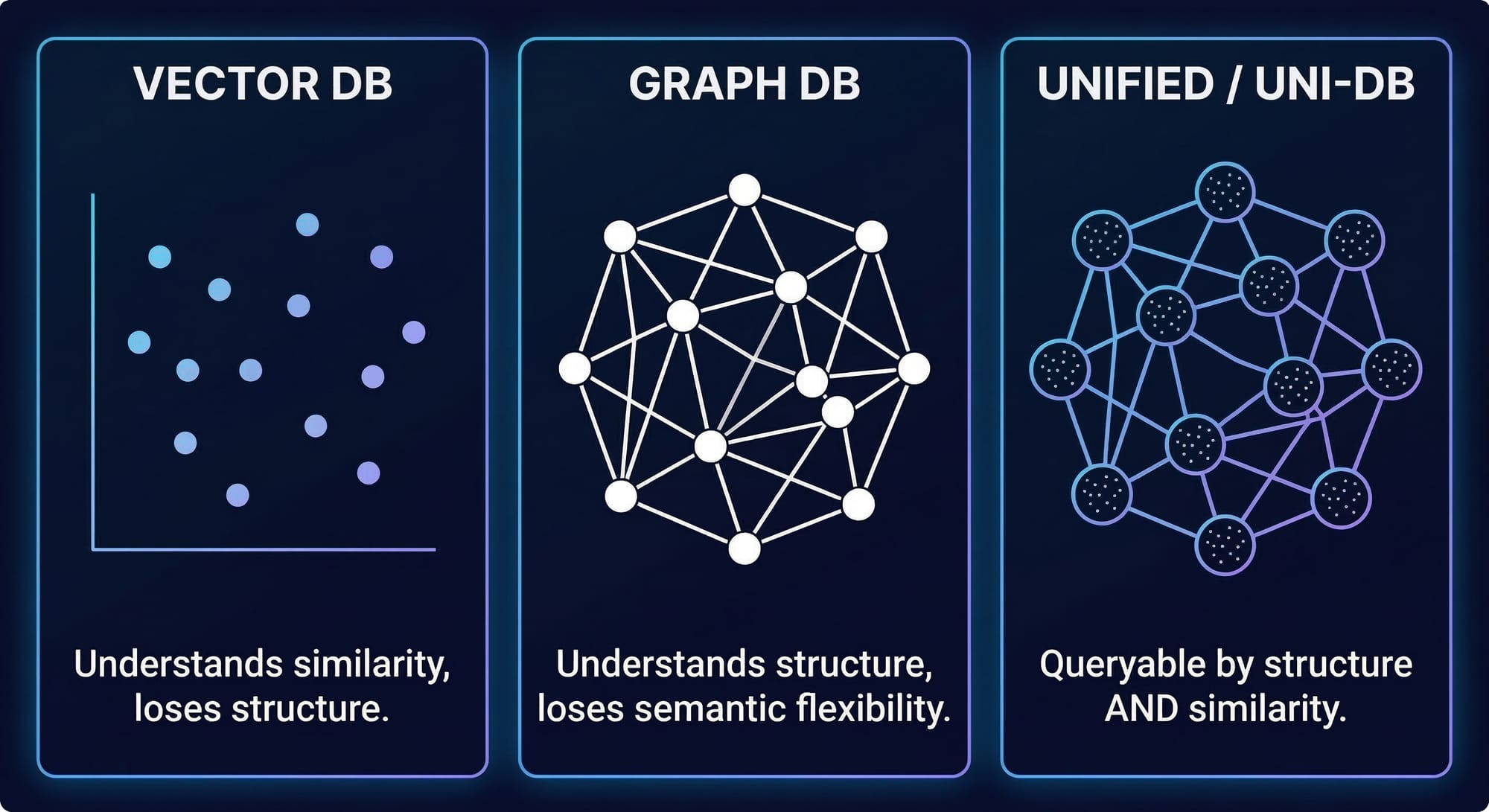
Vector stores capture meaning but lose relationships. They can tell you "this document chunk is semantically similar to your query." They cannot tell you "Alice manages Bob, who has access to the production database, which was last audited six months ago."
Graph databases capture relationships but don't embed. They store structure but can't do semantic similarity search across that structure. A NAACL 2024 survey confirmed that knowledge graphs are the leading strategy for reducing LLM hallucinations — but current KG-based methods "only treat KGs as factual knowledge bases and overlook the importance of their structural information for reasoning."
An agent that needs both ends up maintaining two systems with two data models and no unified query path. Knowledge gets fragmented across storage backends. The agent loses the ability to ask questions that span both structure and meaning.
The gap isn't storage. It's structured memory — a knowledge graph where entities have typed properties, are connected by typed relationships, and are queryable by both structure and similarity in the same operation.
Gap 2: No Formal Reasoning
Chain-of-thought can improve LLM performance on reasoning-like tasks, but it is not a substitute for explicit inference over declared rules and structured state. The model doesn't know your business rules. It approximates plausible ones. SATBench showed that even the strongest frontier model achieves only 65% accuracy on hard logical satisfiability problems — barely above the 50% random baseline. GSM-Symbolic from Apple found that changing only the numerical values in otherwise identical math problems causes up to 65% accuracy drops — LLMs replicate memorized reasoning patterns rather than performing genuine inference.
"Who can transitively access this resource?" is not a retrieval problem. It's a transitive closure computation over a permission hierarchy. The OrgAccess benchmark confirmed that frontier LLMs struggle with exactly this kind of permission-aware reasoning, especially when conflicting constraints arise across organizational hierarchies. "If this supplier fails, what products are at risk?" is not a generation problem. It's risk propagation through a dependency graph with formal rules governing how risk compounds at each hop.
These require declared rules evaluated by a logic engine — the kind of Datalog-derived inference that's been solving exactly these problems in databases and program analysis for decades: if a user has Role X, and Role X inherits from Role Y, and Role Y grants Permission Z, then the user has Permission Z. That's not a prompt. That's a rule — deterministic, reproducible, and evaluable to a guaranteed fixed point.
Chain-of-thought generates tokens that approximate reasoning. Worse, it's often unfaithful: models produce reasoning traces that don't reflect their actual computation. Anthropic's own research found that reasoning models verbalize their actual reasoning hints less than 20% of the time, and independent studies measured CoT unfaithfulness rates of 15–31% on realistic, non-adversarial prompts. Meanwhile, LLM inference is non-deterministic even at temperature zero — accuracy varies up to 15% across runs. Formal inference performs reasoning — with termination guarantees, guaranteed safety for negated rules, and the same answer every time regardless of temperature. For domains where reproducibility and auditability matter, the difference is structural, not cosmetic.
Gap 3: No Hypothetical Planning
Before an agent acts, it should be able to ask "what would happen if I did X?" and get a verified answer — without actually doing X.
Today, agents either act and hope, or they ask the LLM to imagine the consequences. The LLM imagines fluently. It also imagines incorrectly, because it's generating plausible text about a counterfactual state — not computing the actual implications through formal rules. Research on LLM counterfactual reasoning has confirmed significant limitations in models' ability to reliably adjust responses under hypothetical alterations. A UAI 2025 tutorial on counterfactual reasoning positioned structural causal models — not prompt engineering — as the necessary formal substrate for reliable "what-if" analysis.
Real planning in structured domains requires hypothetical reasoning: temporarily assume a set of facts, propagate consequences through all applicable rules, inspect the results, and roll back automatically. The world model stays unchanged. The agent gets verified answers about states of the world that don't yet exist.
Without this, agents operating on structured knowledge can't plan. They can only react. In the book The Myth of Artificial Intelligence, Erik J. Larson identified abductive inference — reasoning backward from goals to discover what must be true — as a fundamental blind spot for current AI. The gap between "react and hope" and "simulate then act" is the gap between a toy demo and a production system.
Gap 4: No Explainable Decisions
"The model said so" is not an audit trail. McKinsey's 2025 survey found that explainability is the second-most-commonly-reported AI risk — yet it is "not among the most commonly mitigated." Deloitte's 2026 State of AI found only 21% of companies have a mature governance model for autonomous agents.
When an agent recommends rejecting a loan, flagging a transaction, rerouting a supply chain, or revoking an access permission, someone needs to know why. Not a confidence score. Not an attention heatmap. A formal derivation chain: this conclusion follows from this rule, which matched these facts, which were retrieved from these graph paths. As Cynthia Rudin argued in her landmark paper, post-hoc explanations of black-box models "must be wrong" — they cannot have perfect fidelity with the original model, because if they did, the explanation would be the model. For high-stakes decisions, inherently interpretable reasoning should replace black boxes with explanations bolted on.
Today, that chain doesn't exist — because the reasoning never happened. The LLM generated an answer that looked right. There's no proof trace because there was no proof. Regulators are already asking for this kind of accountability. The EU AI Act (Article 86) establishes a right to explanation for decisions made by high-risk AI systems that significantly affect individuals. Article 13 requires high-risk systems to be "sufficiently transparent to enable deployers to interpret a system's output and use it appropriately" — with enforcement and penalties up to EUR 35 million beginning August 2026. The NIST AI Risk Management Framework lists "explainable and interpretable" as a core characteristic of trustworthy AI. The Federal Reserve's SR 11-7 guidance on model risk management applies to AI systems in banking, requiring institutions to explain how models use inputs to produce outputs. These aren't aspirational guidelines — they're enforceable mandates, and architectures without formal reasoning cannot structurally comply.
Explainability isn't a nice-to-have bolted on at the end. It's a structural property of how reasoning happens. If the reasoning is token generation, the explanation is a post-hoc justification. If the reasoning is formal inference, the explanation is a derivation tree — auditable, reproducible, and trustworthy.
Let's Get Concrete
The gaps above aren't theoretical. Let's walk through a single scenario to see what an agent with an AI reasoning layer can actually do — and why a RAG pipeline can't.
A security team deploys an agent to answer a routine question: "Who can access the production database, and through which permission chains?"
In the current stack, the agent retrieves policy documents from a vector store, finds chunks mentioning "production database" and "access control," and asks the LLM to synthesize an answer. The LLM produces a confident list of four users. It misses two — because the access was transitive (granted through role inheritance two levels deep), and transitive closure isn't something a vector store computes. This is the hallucination problem in its most dangerous form: not a fabricated fact, but a confidently incomplete answer that looks right and passes review. A Stanford study of production RAG legal research tools found that even products marketed as "hallucination-free" hallucinated 17–33% of the time — and the highest-performing tool was only 65% accurate. The audit passes. The vulnerability stays.
Now ask the same question with Uni underneath.
The agent's structured memory holds the organization as a knowledge graph: users, roles, teams, resources, and the permission edges between them. The rules for access resolution are declared as Locy rules — Uni's Datalog-inspired logic programming language — not prompt-engineered, not embedded in Python glue code. The rule says: if a user holds a role, and that role inherits from a parent role, and the parent role grants access to a resource, then the user can access the resource. Uni evaluates this recursively, chasing every inheritance chain to its fixed point. It returns six users, not four. Every result carries a derivation trace: this user can access this resource because they hold Role A, which inherits from Role B, which grants the permission.
Now the security team asks a harder question: "What happens if we revoke Role B?"
The agent doesn't guess. It uses Uni's ASSUME — a forward simulation primitive. It temporarily asserts "Role B is revoked," re-evaluates all access rules under the hypothetical state, and returns the delta: two users lose production access, one service account loses read permissions, a downstream monitoring job would break. The world model is unchanged — the hypothetical rolls back automatically. The team sees the blast radius before they act.
Then the compliance officer asks: "What's the minimum change to make us SOC 2 compliant on access controls?"
The agent uses Uni's ABDUCE — a backward search primitive. It starts from the desired state (SOC 2 requirements satisfied), searches backward through the rule space for the minimum set of permission changes that would produce that state, and returns a three-step remediation plan: add an approval gate to one role, remove a stale permission from another, restrict a third to read-only.
Every conclusion is explainable via EXPLAIN RULE. Every step has a proof trace. Formal derivation chains from conclusion to base facts.
The twist is that none of this required a more powerful LLM. The same model, with Uni's AI reasoning layer underneath it, went from "confidently wrong" to "verifiably right." The intelligence was always there. The infrastructure wasn't.
The LLM Is System 1. You Need System 2.
The frame that clarifies this division of labor is Daniel Kahneman's System 1 and System 2: fast intuitive pattern recognition on one side, slow deliberate logical inference on the other.
LLMs are extraordinary System 1 machines — they recognize patterns across vast corpora, generate fluent language, and produce responses that feel like reasoning. And they're getting better. Test-time scaling, chain-of-thought, and tool use are real advances that extend what System 1 can reach. But research on test-time scaling has found it is not effective for knowledge-intensive tasks — and can actually increase hallucinations through confirmation bias. Apple's "The Illusion of Thinking" study showed that at high problem complexity, reasoning effort decreases despite adequate token budgets. Thinking harder doesn't solve hard problems.
But for structured, high-stakes domains, feeling is not performing. A comprehensive survey framing the transition "From System 1 to System 2" in reasoning LLMs concludes that even models explicitly designed for deliberate reasoning (o1, o3, R1) have not fully achieved genuine step-by-step logical analysis. Kambhampati, in "(How) Do Reasoning Models Reason?", argues that autoregressive generation fundamentally resembles System 1 — even when it produces reasoning traces. And in the earlier "Can Large Language Models Reason and Plan?", he put it directly: LLM reasoning is approximate, non-reproducible, and can be unfaithful to its own chain-of-thought traces. The model writes the justification after reaching the verdict, not the other way around. His ICML 2024 position paper "LLMs Can't Plan" proposed the solution: LLM-Modulo frameworks where auto-regressive models are paired with external model-based verifiers for deterministic reasoning tasks.
That doesn't mean LLMs are broken. It means they need a complement. The research community calls this neuro-symbolic AI — combining neural pattern recognition with symbolic reasoning. A systematic review of 167 papers on neuro-symbolic AI confirms the field is converging on hybrid integration as the path forward, with research growing from 53 publications in 2020 to 236 in 2023 and accelerating. A survey in IEEE TPAMI validates that combining symbolic reasoning with neural learning outperforms either in isolation. Let the LLM handle language understanding, creative synthesis, and user interaction. Let a reasoning engine handle structured knowledge, formal inference, and verified simulation. Neither replaces the other. Together, they produce agents that are both fluent and correct.
This is the architecture we built Uni to provide.
What Uni Gives Your Agents
Let's tour the engine room. Uni is an embedded graph database with a logic programming engine — five cognitive functions operating on the same data, in the same process, with the same transactional guarantees.
Structured Memory: The Property Graph
Without structured memory, there's nothing to reason over. So Uni starts here: a schema-typed property graph where entities have typed properties, relationships have meaning, and everything is queryable via OpenCypher.
MATCH (u:User)-[:HAS_ROLE]->(r:Role)-[:GRANTS]->(p:Permission)
RETURN u.name, r.name AS role, p.resource, p.action
One query traverses the entire permission chain — no joins, no glue code. Under the hood, it's columnar storage (Arrow/DataFusion) for analytical speed, object-store persistence (S3, GCS, Azure) for durability, and an embedded runtime for zero infrastructure overhead. No servers to babysit. The knowledge graph lives in your agent's process like a brain lives in a body — not wired in from somewhere else.
Associative Recall: Graph + Vector + Full-Text in One Query
Human memory works two ways: by following chains of connections ("who does Alice manage?") and by similarity ("what situations were like this one?"). These work together — not in separate systems.
Uni fuses graph traversal, vector similarity (HNSW, IVF-PQ), and full-text retrieval (BM25) in a single query. Similarity isn't a separate API — it's a first-class expression, usable anywhere you'd use a comparison operator.
MATCH (d:Doc)-[:REFERENCES]->(policy:Policy)
WHERE similar_to(d.embedding, 'access control violations') > 0.8
RETURN d.title,
similar_to([d.embedding, d.content],
[$query_vector, 'SOC 2 compliance'], {fusion: 'rrf'}) AS score
ORDER BY score DESC
Graph traversal, vector similarity, and keyword search — in one query, with reciprocal rank fusion. This is what knowledge graph RAG should look like — not a vector store bolted onto a graph database, but retrieval as a native expression in the query language itself.
Domain Physics: Locy Rules
Every structured domain has rules governing how the world behaves — the physics of permissions, supply chains, compliance, financial networks. Uni's logic programming layer, Locy (Logic + Cypher), encodes these rules as formal, executable declarations.
CREATE RULE effective_access AS
MATCH (u:User)-[:HAS_ROLE]->(r:Role)-[:INHERITS*]->(parent:Role)
-[:GRANTS]->(p:Permission)
YIELD KEY u, p
That rule chases role inheritance to its fixed point — however deep the hierarchy goes. Version-controlled, composable via a module system (MODULE acme.compliance; USE acme.common), and testable — with the engine re-evaluating only the rules affected by newly derived facts.
When an LLM generates tokens that look like reasoning, it's performing theater. When Locy evaluates rules, it's performing inference. The difference is structural. This isn't a niche approach — Google released Mangle, an open-source Datalog extension for deductive database programming, in 2025. Scallop, from Penn's programming languages group, combines Datalog-based logic programming with differentiable provenance semirings — every derived fact carries a formal trace of how it was derived. The logic programming revival is industry-wide because the need is industry-wide.
Mental Simulation: ASSUME and ABDUCE

The physics is encoded. Now you can use it.
ASSUME runs forward simulation: "What happens if I change X?"
ASSUME {
DELETE (r:Role {name: 'SeniorOps'})-[:GRANTS]->(p:Permission)
}
THEN {
QUERY effective_access RETURN user, permission
}
Apply a hypothetical mutation, re-evaluate all rules under the hypothetical state, inspect the results, roll back automatically. Not an LLM imagining consequences — a reasoning engine computing them.
ABDUCE runs backward: "Given a desired outcome, what's the minimum change that would produce it?"
ABDUCE compliant
WHERE system.name = 'ProductionCluster'
RETURN required_changes
The engine searches from the goal to the minimal intervention. The agent doesn't generate candidate plans and hope. It finds the shortest path from here to there.
Together, ASSUME and ABDUCE define the moment before action — the moment agents that plan inhabit, and agents that guess skip.
Explainable Decisions: EXPLAIN RULE
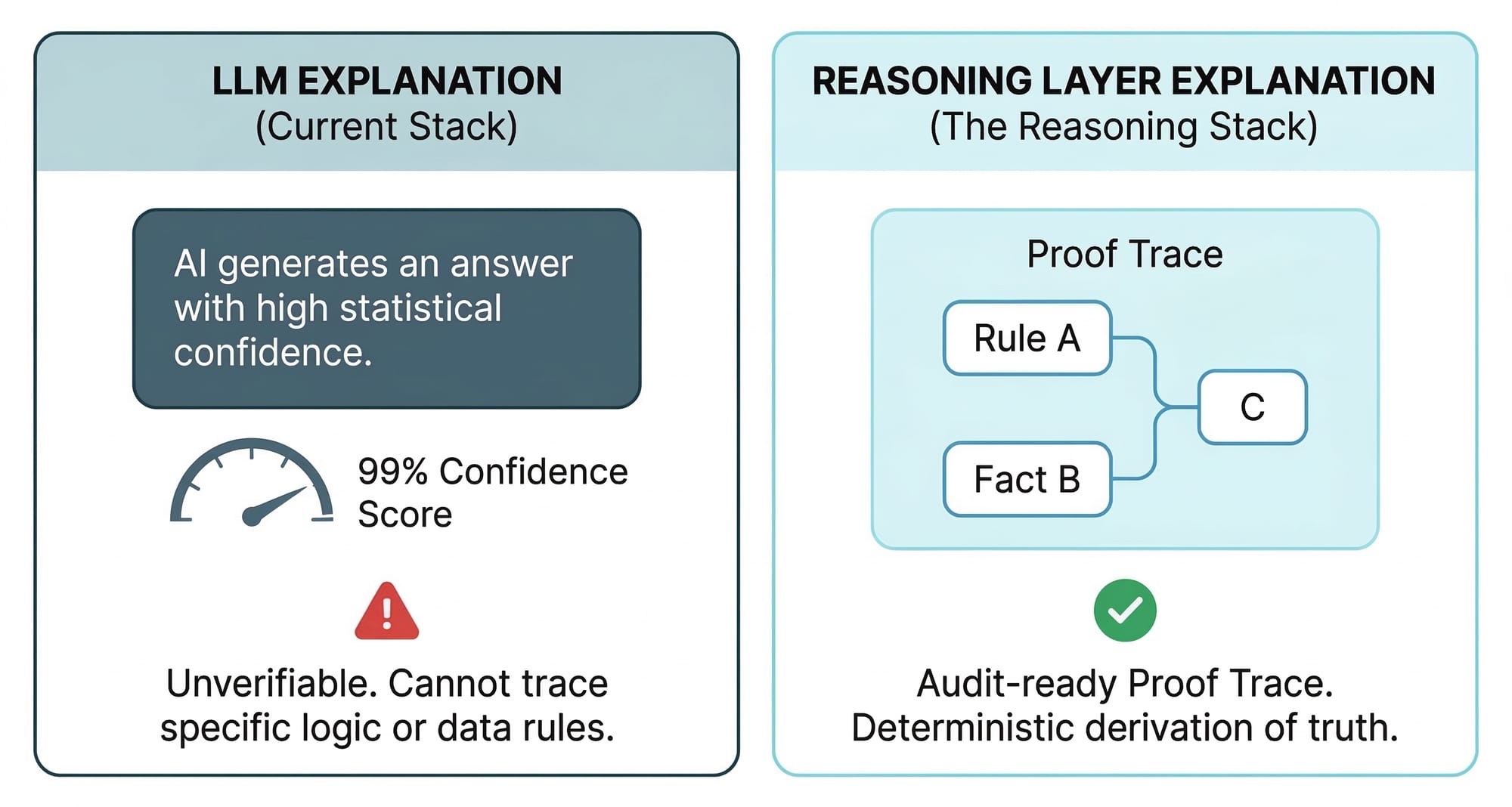
Every conclusion derived through Locy has a complete derivation tree. Not a confidence score. A chain of logic from conclusion to base facts.
EXPLAIN RULE flagged
WHERE account.id = 'ACC-001'
RETURN derivation
"This account was flagged (rule: risk_chain, iteration 3) because it received a transfer from Account X (rule: risk_chain, iteration 2) which was flagged (rule: flagged, base case) because its fraud_score exceeded 0.8."
This is explainable AI as it should work. For compliance: audit trails. For debugging: root cause analysis. For trust: the difference between "trust me" and "here's the proof."
From Three Systems to One Import Statement
The current agent stack tries to assemble cognition from components that were never designed to compose. A graph database for relationships. A vector store for similarity. A rules engine someone hacked together. Three systems, three data models, three failure modes.
Uni collapses this into a single organism. Graph traversals, vector search, full-text retrieval, columnar analytics, formal reasoning, hypothetical simulation, and proof traces — all executing against the same data, in the same process.
No ETL pipelines. No cross-system joins. No network hops between a query and its answer.
One query can traverse a relationship chain, filter by semantic similarity, apply formal rules, and return an explained result. Because it's all one engine. And it runs embedded — pip install uni-db or cargo add uni-db and it's there, in the agent's process. Reasoning at memory speed, not network speed.
Where the Alternatives Fall Short
Each category below solves a real problem — just a different one.
Graph databases (Neo4j, Amazon Neptune) give you relationships and traversal. They're excellent for storing and querying structured data. But they don't do recursive logic programming, hypothetical simulation, or abductive inference. Queries are ad-hoc Cypher statements, not declared rules that compose and propagate. And every query crosses a network boundary — a real constraint for agents running tight decision loops.
Vector stores (Pinecone, Chroma, Weaviate) give you similarity search. They're effective for the retrieval component of RAG. But they can't follow relationship chains, enforce schema constraints, or apply graph algorithms. They answer "what's near this?" but not "what's connected to this, and what rules apply to the result?"
Agent memory systems (Mem0, Zep, Graphiti) give you persistence for agent state. They store and retrieve memories, which is valuable for conversational continuity. But they can't reason over those memories — no formal rules, no simulation, no proof traces. Memory without cognition is a filing cabinet, not a brain.
Agent frameworks (LangGraph, CrewAI) give you orchestration. They decide when the agent thinks and which tools it calls. But the agent still needs somewhere to store structured knowledge and reason over it. Orchestration is necessary but not sufficient — it's the nervous system without the cortex.
Chain-of-thought prompting can improve LLM performance on reasoning-like tasks, and the improvements are real. But for domains requiring reproducibility, auditability, and deterministic correctness, it doesn't provide the guarantees that formal inference does. Research has shown that CoT reasoning is "a brittle mirage" — it vanishes beyond training distributions, and semantically irrelevant perturbations substantially degrade performance. When it's wrong, it's wrong confidently — and you can't distinguish the two cases without external verification. A systematic evaluation of RAG vs. GraphRAG confirms the pattern: GraphRAG outperforms on multi-hop reasoning, but neither architecture provides the formal guarantees that declared rules evaluated by a logic engine can.
We haven't seen a mainstream agent stack that natively unifies structured memory, formal reasoning, hypothetical simulation, backward search, and proof traces in a single embedded engine. That's the gap Uni is designed to close.
What This Changes
When agents have cognitive infrastructure — structured memory, formal reasoning, simulation, explainability — the category of problems they can solve shifts. The payoff is not a faster retrieval pipeline. It's a different class of machine.
A security agent doesn't just retrieve policy documents. It resolves transitive RBAC permissions across a knowledge graph, simulates the blast radius of a compromised credential with ASSUME, and explains exactly which inheritance chain grants which access through EXPLAIN RULE. What used to be a three-day manual audit collapses to a query.
A supply chain agent doesn't just track shipments. It propagates risk through dependency graphs using Locy rules with ALONG for cumulative risk at each hop, simulates supplier failures before they happen, and uses ABDUCE to find the minimum sourcing changes to restore resilience. The planning is verified, not guessed.
A compliance agent doesn't just flag violations. It traces the full derivation chain from a non-compliance finding back to the specific rules and facts that produced it, then searches backward with ABDUCE for the minimal remediation — the smallest change that makes the system compliant. Regulators get proof traces, not probability scores.
A code agent doesn't just generate patches. It models the codebase as a dependency graph, simulates the impact of a refactoring across transitive callers using ASSUME, and explains which paths are affected and why. The developer reviews a verified impact analysis, not the LLM's best guess.
In each case, the pattern is the same: the LLM handles language, creativity, and user interaction. Uni handles structured knowledge, formal inference, simulation, and explanation. Neither replaces the other. Together, they produce agents that are both fluent and correct — a combination that neither can achieve alone.
Start Building
You can keep building agents on the current stack. For many applications — content generation, conversational support, document summarization — it works well. RAG is a good tool for retrieval problems.
But the moment you need your agent to handle structured knowledge — permissions, dependencies, regulations, hierarchies, supply chains — you hit the wall. The agent can't reason over structure. It can't simulate consequences. It can't explain its decisions. It can't compute fixes. No amount of prompt engineering will give it these capabilities, because they require infrastructure, not instructions.
The history of computing is a history of building the right abstraction layer. We didn't make spreadsheets faster by hiring faster accountants. We didn't make databases better by writing better file parsers. We built the infrastructure that made the problem tractable — and problems that had been impossible simply became queries.
An AI reasoning layer is that abstraction for agents. The LLM provides the intelligence. The reasoning layer provides the machinery to aim it — structured knowledge to think about, formal rules to think with, and simulation to think ahead.
The reasoning layer isn't optional. It's what turns an agent that talks into an agent that thinks — and every conclusion it reaches into one it can prove.
Get started: pip install uni-db or cargo add uni-db — see a complete reasoning example that defines rules, simulates a what-if, explains a decision, and computes a minimal fix, in under five minutes.
References
- Agrawal, G., Kumarage, T., Alghamdi, Z., & Liu, H. (2024). "Can Knowledge Graphs Reduce Hallucinations in LLMs? A Survey." NAACL 2024 (Long Papers), pp. 3947–3960. https://aclanthology.org/2024.naacl-long.219/
- Ant Group / OpenSPG Team. (2024). "KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation." arXiv:2409.13731. https://arxiv.org/abs/2409.13731v1
- Arcuschin, I., Janiak, J., Krzyzanowski, R., Rajamanoharan, S., Nanda, N., & Conmy, A. (2025). "Chain-of-Thought Reasoning In The Wild Is Not Always Faithful." arXiv:2503.08679. https://arxiv.org/abs/2503.08679
- Cemri, M., Pan, M. Z., Yang, S. et al. (2025). "Why Do Multi-Agent LLM Systems Fail?" arXiv:2503.13657. https://arxiv.org/abs/2503.13657
- Chen, Y., Benton, J., Radhakrishnan, A., Korbak, T., Kaplan, J. et al. (2025). "Reasoning Models Don't Always Say What They Think." Anthropic Research / arXiv:2505.05410. https://arxiv.org/abs/2505.05410
- Cleanlab. (2025). "AI Agents in Production 2025." https://cleanlab.ai/ai-agents-in-production-2025/
- Deloitte. (2026). "State of AI in the Enterprise 2026." https://www.deloitte.com/us/en/what-we-do/capabilities/applied-artificial-intelligence/content/state-of-ai-in-the-enterprise.html
- Edge, D., Trinh, H. et al. (2024). "From Local to Global: A Graph RAG Approach to Query-Focused Summarization." Microsoft Research / arXiv:2404.16130. https://arxiv.org/abs/2404.16130
- EU AI Act, Article 13 — "Transparency and Provision of Information to Deployers." https://artificialintelligenceact.eu/article/13/
- EU AI Act, Article 86 — Regulation (EU) 2024/1689. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
- Federal Reserve. (2011). SR 11-7 — Guidance on Model Risk Management. https://www.federalreserve.gov/supervisionreg/srletters/sr1107.htm
- Gartner. (2025). "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
- Google. (2025). Mangle: A Datalog Extension for Deductive Database Programming. https://github.com/google/mangle
- Han, H. et al. (2025). "RAG vs. GraphRAG: A Systematic Evaluation and Key Insights." arXiv:2502.11371. https://arxiv.org/abs/2502.11371
- Kambhampati, S. (2025). "(How) Do Reasoning Models Reason?" Annals of the New York Academy of Sciences. https://nyaspubs.onlinelibrary.wiley.com/doi/10.1111/nyas.15339
- Kambhampati, S. et al. (2024). "Can Large Language Models Reason and Plan?" arXiv:2403.04121. https://arxiv.org/abs/2403.04121
- Kambhampati, S., Valmeekam, K., Guan, L. et al. (2024). "Position: LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks." ICML 2024 / arXiv:2402.01817. https://arxiv.org/abs/2402.01817
- LeCun, Y. / AMI Labs. (2026). "Yann LeCun's AMI Labs raises $1.03 billion to build world models." TechCrunch. https://techcrunch.com/2026/03/09/yann-lecuns-ami-labs-raises-1-03-billion-to-build-world-models/
- Li, Z., Huang, J., & Naik, M. (2023). "Scallop: A Language for Neurosymbolic Programming." ACM SIGPLAN (PLDI). https://dl.acm.org/doi/10.1145/3591280
- Li, Z.-Z. et al. (2025). "From System 1 to System 2: A Survey of Reasoning Large Language Models." arXiv:2502.17419. https://arxiv.org/abs/2502.17419
- Luo, L. et al. (2024). "Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning." ICLR 2024 / arXiv:2310.01061. https://arxiv.org/abs/2310.01061
- Magesh, V. et al. (2025). "Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools." Journal of Empirical Legal Studies / arXiv:2405.20362. https://arxiv.org/abs/2405.20362
- Masterman, T., Besen, S., Sawtell, M., & Chao, A. (2024). "The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey." arXiv:2404.11584. https://arxiv.org/abs/2404.11584
- McKinsey & Company. (2025). "The State of AI: How Organizations Are Rewiring to Capture Value." https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
- Mirzadeh, I. et al. (2025). "GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models." ICLR 2025 / arXiv:2410.05229. https://arxiv.org/abs/2410.05229
- MIT Project NANDA. (2025). "State of AI in Business 2025 Report." https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf
- NIST. (2024). AI 600-1 — "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
- OrgAccess Benchmark. (2025). "OrgAccess: A Benchmark for Role-Based Access Control." arXiv:2505.19165. https://arxiv.org/abs/2505.19165
- Richens, J. et al. (2025). "General Agents Need World Models." ICML 2025 / arXiv:2506.01622. https://arxiv.org/abs/2506.01622
- Rudin, C. (2019). "Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead." Nature Machine Intelligence, 1, 206–215. https://www.nature.com/articles/s42256-019-0048-x
- Shojaee, P. et al. (2025). "The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity." NeurIPS 2025 / arXiv:2506.06941. https://arxiv.org/abs/2506.06941
- Singla, A., Sukharevsky, A., & Yee, L. (2025). See McKinsey & Company [24].
- Snell, C., Lee, J., Xu, K., & Kumar, A. (2025). "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters." ICLR 2025 / arXiv:2408.03314. https://arxiv.org/abs/2408.03314
- "Agentic AI: The Age of Reasoning — A Review." (2025). ScienceDirect. https://www.sciencedirect.com/science/article/pii/S2949855425000516
- "Current Practices for Building LLM-Powered Reasoning Tools Are Ad Hoc — and We Can Do Better." (2025). arXiv:2507.05886. https://arxiv.org/html/2507.05886
- "Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens." (2025). arXiv:2508.01191. https://arxiv.org/abs/2508.01191
- "Neuro-Symbolic AI in 2024: A Systematic Review." (2025). arXiv:2501.05435. https://arxiv.org/abs/2501.05435
- "Non-Determinism of 'Deterministic' LLM Settings." (2024). arXiv:2408.04667. https://arxiv.org/abs/2408.04667
- "On the Eligibility of LLMs for Counterfactual Reasoning." (2025). arXiv:2505.11839. https://arxiv.org/pdf/2505.11839
- "Test-Time Scaling in Reasoning Models Is Not Effective for Knowledge-Intensive Tasks Yet." (2025). arXiv:2509.06861. https://arxiv.org/abs/2509.06861
- Tang, Y. & Yang, Y. (2024). "MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries." COLM 2024 / arXiv:2401.15391. https://arxiv.org/abs/2401.15391
- Turpin, M., Michael, J., Duvenaud, D., & Rush, A. S. (2023). "Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting." NeurIPS 2023 / arXiv:2305.04388. https://arxiv.org/abs/2305.04388
- UAI 2025 Tutorial. "Counterfactuals in Minds and Machines." MPI-SWS. https://learning.mpi-sws.org/counterfactuals-uai25/
- Wang, W., Yang, Y., & Wu, F. (2024). "Towards Data-and Knowledge-Driven Artificial Intelligence: A Survey on Neuro-Symbolic Computing." IEEE Transactions on Pattern Analysis and Machine Intelligence. https://ieeexplore.ieee.org/document/10721277/
- Wei, A. et al. (2025). "SATBench: Benchmarking LLMs' Logical Reasoning via Automated Puzzle Generation from SAT Formulas." EMNLP 2025. https://aclanthology.org/2025.emnlp-main.1716/
- Zhang, Y. et al. (2024). "Can LLM Graph Reasoning Generalize beyond Pattern Memorization?" Findings of EMNLP 2024. https://aclanthology.org/2024.findings-emnlp.127/