
Direct Preference Optimization

The Evolution of Model Fine-Tuning
Techniques for fine-tuning of foundation models, such as Large Language Models (LLMs), have undergone evolution. Initially, models were trained further on a specific dataset to enhance their performance on desired tasks. This process, though effective, often required extensive datasets and was not always efficient in terms of compute resources or time.
The introduction of Reinforcement Learning from Human Feedback (RLHF) marked a major shift. RLHF is a more complex and nuanced approach involving training models based on qualitative feedback and steering them towards outputs that align more closely with human preferences. This method allows for the refinement of models to perform tasks in ways that better reflect human values and intentions. However, RLHF is not without its challenges. It entails the intricate process of training a reward model to interpret human feedback, which is then used to fine-tune the language model. This multi-stage procedure introduces additional complexity, potentially hampering the scalability of model fine-tuning.
Direct Preference Optimization (DPO) is a newer approach that streamlines the model fine-tuning process. DPO directly incorporates human preference data into the optimization process, bypassing the need for a separate reward model. This method simplifies the pipeline and enhances stability and performance by directly optimizing the model's outputs to align with human preferences. DPO fits within a broader trend of leveraging more direct and straightforward optimization methods to refine models.
Understanding DPO
DPO simplifies the process of aligning models with human preferences by optimizing directly on binary preference data, where human judges have indicated a preference between pairs of model-generated outputs.
The fine-tuning of models with RLHF involved a cumbersome, two-step process. First, a reward model had to be trained to interpret and quantify human feedback. Then, this reward model was used to guide the fine-tuning of the primary model towards outputs that aligned with human preferences. This process, while effective, introduced complexity and inefficiency, necessitating the training and maintenance of separate models.
DPO, in contrast, integrates preference learning more directly. By leveraging a theoretical framework such as the Bradley-Terry model, which quantifies the probability of one item being preferred over another, DPO bypasses the need for a separate reward model. Instead, it adjusts the primary model's parameters to increase the likelihood of generating the preferred outcomes. This is achieved by using the binary preference data to compute a loss function that guides the optimization process. The original DPO paper illustrates the difference as follows:
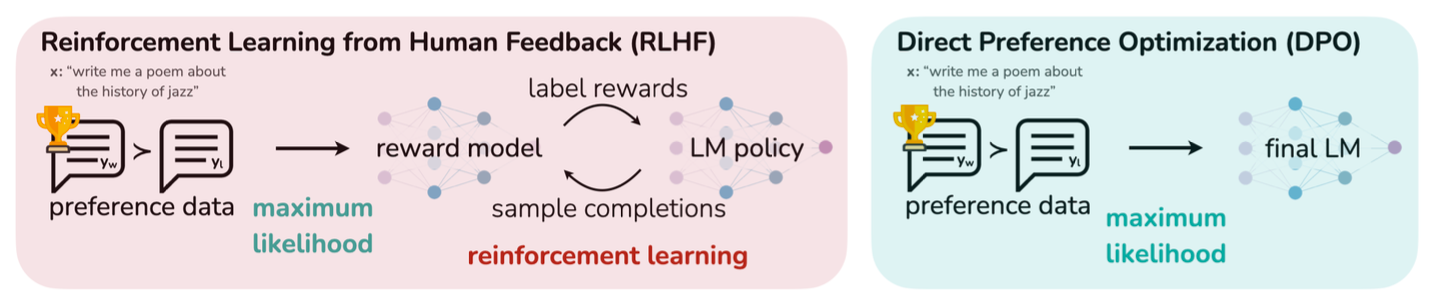
This direct approach has several advantages. Firstly, it reduces the complexity of the fine-tuning pipeline by eliminating the need for a separate reward model. This reduces the computational resources and time required for training. Secondly, by optimizing directly on human preferences, DPO can more effectively align model outputs, potentially leading to better model performance.
DPO's methodology represents a more intuitive approach to incorporating human feedback into model training. By directly mapping binary preference data onto the model's optimization process, DPO ensures that the fine-tuning process is closely aligned with the explicit preferences expressed by human judges.
DPO in Action
DPO has shown considerable promise in practical applications, with empirical evaluations demonstrating its effectiveness across a range of tasks including sentiment modulation, summarization, and dialogue, which are common uses of language models.
In sentiment modulation tasks, DPO has been employed to fine-tune language models to generate text that aligns with a desired sentiment. For example, in generating product descriptions or customer service responses, ensuring that output reflects a positive sentiment can significantly impact customer satisfaction. DPO's direct optimization on binary preference data allows for better alignment of outputs with the target sentiment. This direct approach has been shown to surpass traditional RLHF methods.
Summarization tasks, used in information retrieval, news aggregation, and content creation, have also benefited. DPO has enabled the development of models that produce summaries more aligned with what users find useful and informative. DPO-fine-tuned models have demonstrated improved capabilities in capturing the essence of articles or discussions, producing summaries that are concise and more reflective of the content's perceived importance.
In dialogue applications, from virtual assistants to customer support bots, the ability to generate human-like, engaging, and helpful responses is important. DPO has been applied to fine-tune dialogue models to better reflect human conversational preferences. DPO enhances the models' ability to engage in more natural, contextually relevant, and satisfying interactions.
By enabling more efficient and effective alignment with human preferences, DPO supports the use of language models in areas where nuanced understanding and generation of human-like text are critical. The simplification and efficiency brought by DPO hold the promise of accelerating the development of models, making it possible for more organizations to customize models for specific applications.
DPO's Future Impact
DPO is likely to accelerate the development and deployment of AI applications. The simplification of fine-tuning opens the door for smaller teams and organizations to participate in the development of customized AI solutions. DPO's ability to align AI systems with human preferences may make AI more responsive and user-friendly. DPO could improve the user experience across applications from virtual assistants and customer support bots to content creation tools.
DPO's methodology may inspire new approaches in AI research and development, particularly in areas requiring nuanced understanding and generation of human-like text. Its could be developed into novel methodologies in other aspects of AI, such as computer vision and robotics, where understanding and responding to human feedback and preferences are also important.
DPO could also be adapted for real-time applications. In scenarios where immediate feedback and adaptation are critical—such as in autonomous vehicles, real-time translation, or interactive learning environments—DPO could help to achieve the levels of performance required.
Getting Started with DPO
If you are a developer or researcher involved in model fine-tuning, a number of resources are available. Here’s where to look to get started.
GitHub Repositories
You can find reference implementations of DPO with examples that works with HuggingFace model in this GitHub repository.
The implementation of a further refinement of DPO with examples and documentation is in this GitHub Repository.
Research Paper
The original DPO paper is available here.
Using these resources, you can get started using Direct Preference Optimization for model fine-tuning.