
What Is Goal-Native AI? The 2026 Architecture for Governed Autonomy

There's a seductive pitch making the rounds: "Just add agents."
Bolt autonomous AI onto your existing systems. Let it reason, plan, act. Watch the magic happen.
It's the same theater as RPA, chatbots, and copilots. The technology works in demos; production stalls. The pattern isn't bad technology—it's architectural mismatch.
In Why Workflows Fail, we diagnosed deterministic scripts colliding with indeterministic reality. In Adaptive Enterprise Architecture, we mapped six principles that work with variance instead of against it.
But principles aren't products. Here's the tension: Manual governance doesn't scale—humans can't replan 200 tickets every 15 minutes. Traditional automation doesn't bend—workflows shatter on variance. Autonomous agents bend without guardrails—adaptive, yes; deployable in regulated environments, no.
Every enterprise leader faces this trilemma. You can have governance (workflows) or adaptability (agents), but not both—at least, not with inherited architectures.
The answer isn't faster workflows or smarter agents. It's a different primitive—one that treats governance and adaptability as complements rather than tradeoffs.
Goal-Native AI declares outcomes, enforces constraints, and discovers tactics continuously within those boundaries. Governed autonomy that adapts without breaking compliance.
Put technically: the runtime is a reconciliation loop over business metrics—continuously comparing desired state to actual state—with policy-enforced action boundaries. Not "agents with vibes." Control loops with governance.
Why the Alternatives Fail
"Smarter Workflows"—Same Container, Faster Collapse
The intuitive response to workflow failure is workflow improvement. Add AI copilots. Put an LLM at decision gateways. Sprinkle intelligence everywhere.
This inherits every problem from Why Workflows Fail. You're still prescribing sequences; you're just executing them faster. Gartner reports that more than 50% of generative AI projects fail. McKinsey's 2025 State of AI confirms the pattern: while 88% of organizations now use AI, only 39% report enterprise-level financial impact. Efficiency gains never translate to outcomes because the surrounding architecture remains unchanged.
If you squint, you can see why. The workflow remains the unit of work. AI accelerates steps but can't question whether those steps make sense. When reality shifts—a supplier delays, a customer escalates, a regulation changes—the workflow continues its predetermined march, now faster, toward the wrong destination.
W. Edwards Deming identified this decades ago: "The central problem in lack of quality is the failure of management to understand variation." Workflows fail not because workers deviate from the script but because the script can't accommodate the variety inherent in real operations.
"Putting a jet engine on a horse-drawn carriage doesn't make it an airplane. It makes an expensive, dangerous carriage."
"Autonomous Agents"—Flexibility Without Guardrails
The opposite intuition: abandon workflows entirely. Deploy autonomous agents that reason, plan, and adapt.
This solves brittleness but creates ungoverned autonomy. No budget constraints enforced at execution. No compliance checks before actions fire. No audit trail connecting intent to outcome. No way to explain to the board why the system did what it did.
The 2025 data is sobering. Early enterprise agent deployments have shown patterns of unintended system access, inappropriate data exposure, and actions that exceeded intended scope.
You can't deploy what you can't explain. You can't explain what you can't govern. You can't govern what operates outside policy boundaries.
Explainability here means each action logs the triggering metric gap, constraint checks performed, tools invoked, and outcome delta. Not "the AI decided"—but "the system closed a 2.1h→1.8h response time gap by expanding auto-response from 80% to 92%, within PII policy, at $41/ticket cost."
The Gap
Workflows: governed but brittle. Agents: adaptive but ungoverned. Neither fits enterprise reality.
Goal-Native AI occupies the space between: governed autonomy.
The twist? Guardrails don't limit capability—they enable deployment. Gartner predicts that 40% of enterprise applications will embed agents by 2026, but only with governance that makes deployment viable. The constraint that seems restrictive makes the system trustworthy enough to run unsupervised.
The Cybernetic Foundation
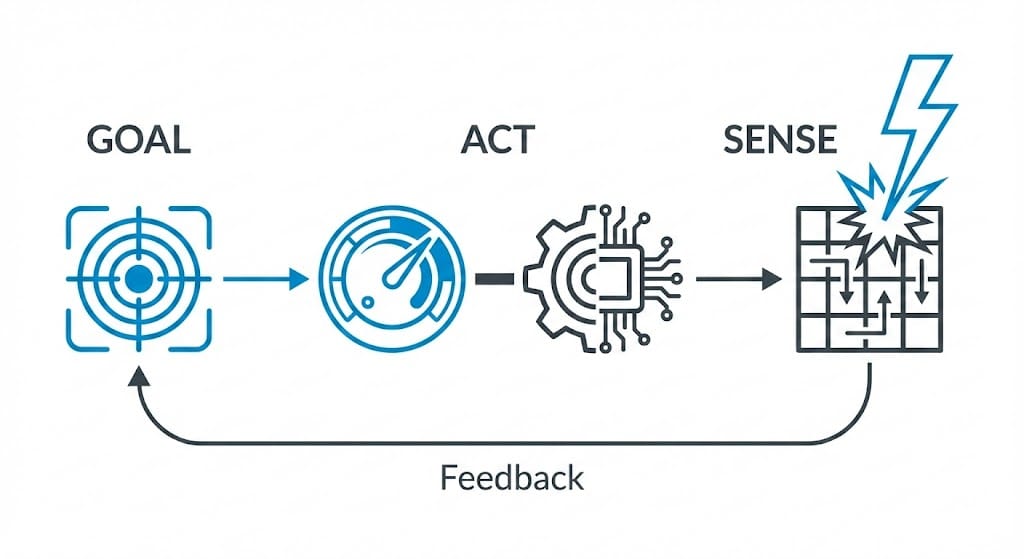
Your thermostat doesn't follow a script.
It doesn't say, "Turn on heating at 8am. Run for 2 hours. Turn off." That's a workflow—a predetermined sequence that ignores reality.
Instead, it declares a goal: maintain 68°F. Then it senses continuously. Sunlight warms the room? It backs off. Window opens? It compensates. Occupancy changes? It adapts.
The what is fixed. The how is discovered moment by moment.
This isn't metaphor. It's the founding insight of cybernetics—the science Norbert Wiener established in 1948. Goal-directed behavior emerges from feedback loops: sense the gap between current and desired state, act to close it, sense again.
Goal-Native systems are thermostats for business outcomes.
Ashby extended this with his Law of Requisite Variety: a controller must have at least as much variety (possible responses) as the system it's controlling. Rigid workflows fail Ashby's test—they can't match the variety of real-world situations. Goal-Native systems, operating freely within guardrail boundaries, can.
Let's Get Concrete
Support operations. The workflow says, "Route to L1. Wait 30 minutes. Escalate to L2." Rigid steps that ignore whether the customer runs a $50K account or a free trial, whether it's a billing question or a security incident, whether L1 is slammed or idle.
The Goal-Native version: "Maintain ≤2h median response time at NPS ≥60." The system senses queue depth, agent load, ticket urgency, customer value—and adapts in real time. A VIP with a security issue jumps the queue. A password reset auto-resolves. The tactics shift; the target holds.
Manufacturing quoting. The workflow prescribes, "OCR the drawing. Look up BOM. Check margin. Route to compliance." Each step assumes stability; any variation triggers exceptions that pile up in someone's inbox.
The Goal-Native version: "Return quote in ≤10 minutes with margin ≥15%." The system orchestrates whatever achieves that—parallelizes lookups, caches frequent components, auto-approves standard configurations. When a supplier's lead time changes mid-quote, it replans invisibly. The salesperson sees a quote; the system handled the chaos.
"The workflow encodes how. Goal-Native encodes what and within what bounds. The difference isn't semantic—it's architectural."
Goals + Guardrails
Two primitives replace the workflow's step-and-approval model:
Goals define desired states, not step sequences. Not "send follow-up on day 3" but "maintain pipeline ≥$5M at CAC <$200 over a rolling 90-day period." Measurable, time-bound, continuously monitored. As Donella Meadows identified, "the goal of the system is a high leverage point"—changing goals changes everything downstream.
Guardrails are policy constraints, not approval gates. Not "manager must approve expenses over $500" but "spend ≤$500 without approval; pause above that." Boundaries within which the system operates freely. (We explore this shift in depth in Guardrails Over Governance.)
You declare what to achieve and how not to do it. The system discovers how, continuously, within those constraints. That's the interface. Everything else is implementation.
This pattern is gaining traction under names like "Spec-Driven Development." GitHub's engineering team notes, "Specification provides a guide for AI agents to work from, refer to, and validate their work against—a North Star allowing it to take on larger tasks without getting lost." Emerging tools (GitHub Spec Kit, AWS Kiro, the BMAD Method) follow the same structure: Intent → Spec → Plan → Execution.
Goal-Native applies this to business operations: the spec is the goal plus guardrails; the plan is the tactics; execution adapts continuously while the spec holds stable.
Stafford Beer anticipated this decades ago: operational units should have "as much autonomy as possible, limited only by the requirements of system cohesion." Goals define cohesion. Guardrails define its boundaries. Within those boundaries, the system has full freedom to match environmental complexity.
Why "Goal-Native" and Not Just "Goal-Oriented"
There's a difference between systems that are goal-oriented and systems where the goal is the executable primitive.
Goal-oriented systems use goals as reference points. An agent with a goal like "increase retention" generates tasks, executes them, checks progress, and regenerates tasks. The goal informs execution, but the executable unit remains the task. Translation layer: goal → tasks → execution.
Spec-driven development uses specs as blueprints. You write a spec, AI generates code, you run the code. The spec guides generation, but the executable unit remains the code. Translation layer: spec → code → execution.
Goal-Native systems make the goal itself the executable. You don't execute tasks toward a goal; you execute the goal directly. The system continuously runs the goal—sensing the current state, comparing to the target, discovering whatever tactics close the gap, and acting on them. No translation layer. The goal IS what runs.
This isn't novel. It's how Kubernetes works: the desired state declaration isn't a blueprint for scripts—it's what the reconciliation loop continuously executes. "The controller's responsibility is to bring actual state in line with desired state—continuously. Kubernetes is a closed-loop system." (For more on why execution—not planning—must be the system of record, see Actuation-First Architecture.)
It's how Prolog works: you query a goal directly; the engine executes through unification and backtracking. No translation to procedural steps.
It's how SQL works: you declare what you want; the database executes the declaration directly. The optimizer discovers the how; you specify the what.
Goal-Native applies this to business operations. The goal—"maintain ≤2h response time at NPS ≥60"—isn't a document informing task generation. It's a runtime primitive the system continuously executes. When variance hits, there's no regeneration step, no translation latency. The system already executes the goal; it adapts tactics within guardrails.
"Goal-oriented: goals inform what tasks to execute. Spec-driven: specs inform what code to generate. Goal-Native: goals ARE what executes."
Goal-Native vs the Alternatives
The Comparison
| Dimension | Workflows | Autonomous Agents | Goal-Native |
|---|---|---|---|
| Primitive | Steps | Actions | Outcomes |
| Adaptation | Manual redesign | Unbounded | Continuous within policy |
| Guardrails | Approval gates | Minimal | Policy-based boundaries |
| Failure mode | Brittle collapse | Unpredictable drift | Graceful replan |
| Auditability | Implicit logs | Inconsistent | Goal-linked action trace |
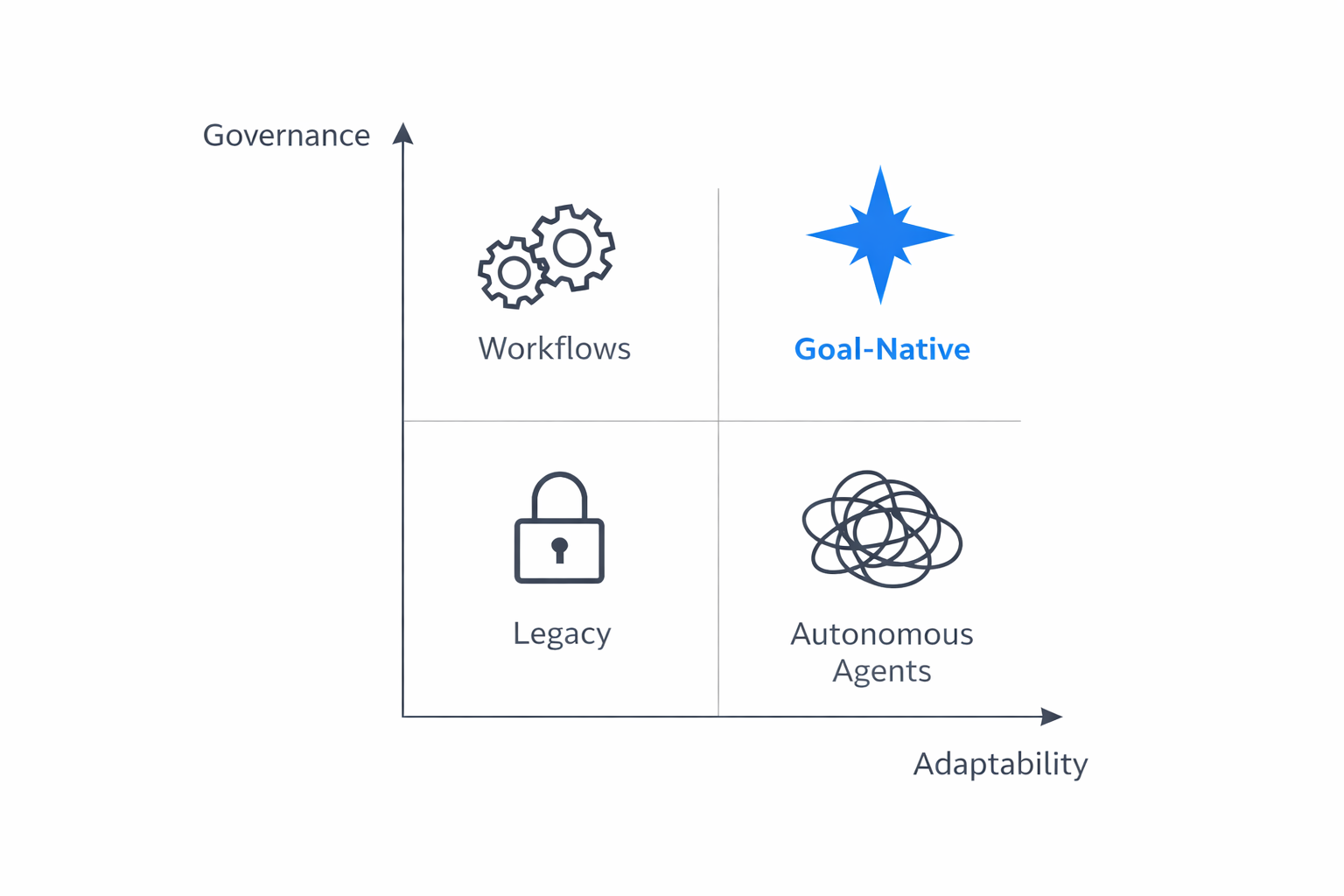
The Architecture Space
Goal-Native occupies the upper-right: high adaptability and high governance. Not a compromise—a synthesis.
Agentic AI vs Goal-Native
Agentic AI describes capability—AI that reasons, plans, and acts. "Goal-Native" describes architecture—how you organize systems around outcomes with policy as governance.
The ACL 2025 survey on LLM planning observes, "Traditional LLMs optimize for the most convincing next sentence. An agentic LLM optimizes for the most effective next action—moving from systems of language to systems of behavior." But behavior without boundaries isn't deployable. Goal-Native provides the guardrails that make deployment possible.
The long-horizon planning community has converged on similar patterns. "Plan-and-Act" separates planning (reasoning, decomposition) from execution (runtime flexibility within plan boundaries). "Thoughts Management System" enables agents to "dynamically prioritize goals, decompose objectives into actionable tasks, and adapt strategies over extended periods." These aren't workflow steps. They're goal-directed structures that adapt.
"Agentic AI is the engine. Goal-Native is the airframe. You wouldn't fly a jet engine without the airframe that makes it controllable."
Under the Hood: Handling a Support Spike
Let's tour the architecture through a scenario. In Adaptive Enterprise Architecture, we showed a support operation during a promotional spike. Traditional architecture: $338K in damage, 11-day recovery. Here's the same scenario under Goal-Native.
The Contract
Goal: "Maintain support response quality"
Metrics: median_response ≤ 2h, NPS ≥ 60
Guardrails: cost_per_ticket ≤ $50, no PII in auto-responses,
human review if sentiment < -0.5 or value > $10K
Everything else adapts to maintain this.
Day 1: Normal Operations
1,200 tickets. The system routes by complexity and agent skill—not by workflow step but by what moves the goal metric. Auto-drafts 80% of simple queries within policy bounds. Health assessment: On Track.
The system isn't following a routing script. It's continuously optimizing toward ≤2h response time while respecting guardrails. Tactics emerge from the goal, not from predetermined sequences.
Day 2: The Spike
A promotion launches. 3,100 tickets by noon—2.5x normal volume.
The health loop detects trajectory drifting toward 4h response time by end of day. Status shifts to At Risk.
Here's where Goal-Native diverges from both workflows and ungoverned agents. A workflow would continue its predetermined routing—L1, wait, L2—and collapse under volume. An ungoverned agent might violate cost constraints or skip compliance checks to clear the queue.
A goal-native system replans within guardrails:
- Expands auto-response to 92% for promo-related queries (within PII policy)
- Prioritizes by customer value (high-value accounts get faster human review)
- Routes to London team coming online (cross-timezone capacity)
- Deploys promo-specific templates (cached from past promotions)
This is Model Predictive Control (MPC) applied to business operations—the same approach governing autonomous vehicles. Optimize over a prediction horizon, execute only the current action, replan continuously as conditions change. MPC is battle-tested in autonomous vehicle systems and industrial control; Goal-Native extends it to organizational decision-making.
The Fresh-Context Advantage
Standard agent loops suffer from context accumulation—every failed attempt, edge case, and exception stays in conversation history. After enough iterations, the model processes a long history of noise before focusing on the current task.
The emerging "Ralph Loop" pattern solves this by starting each iteration fresh, using external state (filesystems, databases, and goal metrics) as the memory layer rather than accumulated conversation history. Goal-Native applies the same principle: each replanning cycle starts fresh, reads current state from the goal registry and memory system, and plans forward without context pollution from previous attempts.
Completion criteria come from external goal metrics, not from the LLM's self-assessment. If the LLM thinks the task is complete but the metric says otherwise, the system keeps working. This prevents "delusional completion"—agents declaring victory prematurely.
Within 20 minutes—no human notified, no meeting scheduled—tactics adapt while constraints hold. By end of day: 2.1h median response time, NPS 61, average cost $41/ticket. All guardrails satisfied. Status: On Track.
Day 3: Memory Compounds
Volume normalizes. The system scales back automatically—no one needs to remember to "turn off" the emergency measures.
But here's the payoff workflows can't match: the system's memory captured the episode. What worked: expanded automation plus cross-timezone routing. What triggered the spike: promo launches correlate with 2–3x volume. What to do next time: pre-position capacity before similar promos.
Modern agent memory architectures distinguish three types of memory that mirror human cognition:
- Episodic memory: What happened—the specific events, contexts, and outcomes of this spike
- Semantic memory: What things mean—the relationships between promos, volume patterns, and resolution strategies
- Procedural memory: How to do things—the proven playbook for handling promotional spikes
This graduates from episodic (what happened) to semantic (what it means) to procedural (what to do). The pattern isn't just logged—it's learned. Research systems like AriGraph and Zep construct knowledge graphs connecting these memory types, enabling systems to reason about past episodes when facing new situations.
Next promotion, the system doesn't relearn from scratch. It starts from the proven playbook and adapts from there.
In workflow land, this knowledge lives in people's heads or dies when they change roles. In Goal-Native land, it's organizational memory that compounds. Each spike handled makes the next one easier. Each edge case resolved adds to the playbook. The system gets smarter not just because it computes but because it remembers.
The Difference
| Metric | Traditional | Goal-Native |
|---|---|---|
| Peak response time | 18 hours | 2.3 hours |
| Recovery | 11 days | Same day |
| Total cost | $338K | ~$2K |
| Learning captured | In people's heads | In system memory |
Cost modeling assumes: 2,500 excess tickets at $45/ticket fully-loaded labor, 15% customer churn risk on delayed responses valued at $8K average LTV, SLA penalty exposure, and 11 days of overtime staffing. Goal-Native cost reflects incremental compute and expanded automation within existing infrastructure.
"The goal didn't change. The guardrails didn't change. The tactics adapted continuously within both. That's governed autonomy."
What Changes for Humans
Goal-Native doesn't eliminate human roles—it transforms them.
Inner Loop / Outer Loop
The clearest way to understand the shift: humans move from the inner loop to the outer loop.
Inner loop: Fast, frequent feedback cycles—monitoring status, adjusting tactics, and handling routine exceptions. This is where workflows trapped humans: approving tickets, signing off on escalations, and triaging queues.
Outer loop: Slow, strategic cycles—setting goals, defining constraints, and refining policy based on outcomes. This is where human judgment matters.
One analysis observes, "Fast inner loops (status, communication, and risk monitoring) can run at machine speed. The slow outer loop (project lifecycle, stakeholder relationships, and strategic judgment) remains human. The agent runs the inner loops and feeds intelligence up to the human, who runs the outer loop and sends decisions down."
Goal-Native makes this boundary explicit. The system handles the inner loop—continuous monitoring, tactic adaptation, and routine execution. Humans handle the outer loop—goal definition, guardrail refinement, and exception policy. This dynamic—what we call Co-Motion—means humans and AI don't pass a baton; they move together around the same goal, often through Dynamic Guilds that self-assemble around active objectives. The result isn't humans removed from the process but humans focused on decisions that require human judgment.
From Approvers to Governors
In workflow land, humans are approval gates. Every exception routes to someone's inbox. Every deviation requires sign-off. The work is reactive: approve, reject, and escalate. One senior operations manager reported spending four hours daily triaging escalations—not solving problems, just deciding who should solve them.
In Goal-Native land, humans are governors. They set goals and guardrails upfront, then monitor health rather than transactions. The work is strategic: define constraints, review edge cases, and refine policies based on outcomes.
Herbert Simon won a Nobel Prize for identifying why this matters. "Bounded rationality" recognized that human decision-making is limited by cognitive capacity, available information, and time. Workflows were designed for these limitations: humans couldn't consider every variable, so we encoded the variables we could handle into scripts.
Goal-Native extends human intention beyond human attention span. You define what you want (goals) and what you won't accept (guardrails). The system handles the continuous optimization that exceeds human cognitive bandwidth.
If you squint, this mirrors how executives already think. No CEO approves individual purchase orders; they set budget constraints and review spend patterns. No CFO signs every invoice; they define approval thresholds and audit exceptions. Goal-Native extends that model to operational systems, pushing governance to the edges while keeping humans at the center of policy.
The result isn't fewer humans in the loop but humans in a different loop—one where attention goes to judgment calls that matter, not routine approvals that don't.
From Status Reports to Health Dashboards
Weekly status meetings become irrelevant when health is continuously visible. Instead of asking, "What happened last week?" you ask, "Which goals are at risk?" Instead of updating spreadsheets, you investigate trajectory changes. Instead of preparing slides summarizing what everyone already knows, you focus on anomalies that need human judgment. (See Goal Health Beats Project Status for why probabilistic health scores replace traffic-light dashboards.)
The status theater from Why Workflows Fail—the green-yellow-red grids, the ritualized recitations—collapses when the system itself surfaces where attention is needed. You don't need a meeting to discover the pipeline is at risk; the dashboard shows it in real time, with contributing factors already identified.
Meeting culture shifts from status-sharing to decision-making. The information is visible; the question becomes what to do about it.
From Process Designers to Constraint Architects
The expertise that used to go into drawing workflow diagrams shifts to defining goal metrics and guardrail policies. What outcomes matter? How do we measure them? What constraints are non-negotiable? What boundaries enable flexibility?
This is harder than drawing flowcharts. It requires understanding what the business values, not just how work currently flows. You can't define a good goal metric without knowing what success looks like. You can't set meaningful guardrails without understanding the risks that matter.
But it's more durable—goals and constraints change far less often than step sequences. A workflow might need revision every time a tool changes, a team reorganizes, or a new edge case surfaces. A goal ("maintain ≤2h response time at NPS ≥60") remains stable even as tactics evolve.
The new skill isn't process mapping—it's constraint thinking. What boundaries create good outcomes? What flexibility enables adaptation? Where do humans need to stay in the loop, and where can systems be trusted? These questions are architectural, not procedural, and the answers compound over time as the organization learns what works.
When Goal-Native Fits
Not every problem needs this architecture. The Cynefin framework helps identify where it fits.
In Complicated domains—where cause and effect are discoverable through analysis—workflows can work. Expert analysis yields correct answers. A tax calculation, a regulatory filing with fixed rules, and a manufacturing process with tight tolerances—analyze, design the workflow, and execute.
In Complex domains—where cause and effect are only visible in retrospect—workflows break. Customer behavior, market dynamics, and supply chain disruptions—you can't analyze your way to the right answer because the answer emerges from interaction. The right approach is probe, sense, and respond—exactly what Goal-Native does.
Most enterprise operations exist in the Complex domain. That's why workflows fail so consistently—they assume Complicated (predictable cause-effect) when reality is Complex (emergent cause-effect).
You're a fit if:
Success is measured in outcomes—customer retained, deal closed, and threat neutralized—not activities completed. Variance is your norm, not your exception. You need to explain why decisions were made, not just that they happened. Decision volume outpaces the humans available to approve them.
You're not a fit if:
Processes are genuinely stable and low-variance—some manufacturing lines, some data pipelines. Your domain requires step-by-step documentation for compliance—certain pharma processes, certain legal filings. The entire point is irreducible human judgment—final legal decisions, medical diagnoses, or creative direction.
Best-fit domains: Revenue operations, customer support, supply chain, quote-to-cash, incident response, procurement.
The pattern: high variance, high stakes, guardrails required, scale that exceeds human coordination.
How Goal-Native Fails Safely
No architecture eliminates failure. Goal-Native shifts how systems fail—from catastrophic collapse to contained degradation.
Metric gaming. The system optimizes for the metric, not the intent. Counter: Multi-metric objectives (response time AND NPS AND cost); periodic human review of tactic patterns; anomaly detection on metric trajectories.
Proxy drift. The measurable proxy diverges from the underlying goal. Counter: Layered metrics (leading + lagging indicators); regular goal audits; human-in-the-loop for goal redefinition.
Tool permission creep. The system accumulates capabilities beyond intended scope. Counter: Least-privilege tool access; runtime policy enforcement; capability audits tied to goal boundaries.
Reward hacking. Edge cases where technically valid tactics violate intent. Counter: Guardrail tests in staging; canary deployments for new tactics; human review triggers on novel action patterns.
Vendor lock-in. Goals and constraints become tied to proprietary implementations. Counter: Goals and guardrails as portable specifications (not platform-specific configs); standard interfaces for metric ingestion and action execution.
The security and governance question isn't "will it fail?" but "will we know when it fails, and will the blast radius be contained?" Goal-Native answers both: continuous health monitoring surfaces degradation early; guardrails bound the damage.
From Steps to Outcomes
Most enterprise systems fail for the same reason: they assume the world will behave.
This article is part of a broader exploration of why that assumption breaks—and what replaces it when volatility becomes the norm.
Earlier work examined why workflows collapse under real-world variance. The problem wasn’t poor execution or underpowered tools; it was architectural. Static sequences can’t survive indeterministic reality, which is why more than half of enterprise automation efforts stall or fail.
From there, we explored what an adaptive architecture actually requires: systems with mechanical sympathy for how businesses really operate. Architectures that expect variance instead of fighting it. Principles that allow systems to bend without breaking.
This article completes that arc.
Goal-Native is the architecture that operationalizes those principles. Goals replace steps. Guardrails replace gates. Governed autonomy that adapts without breaking compliance.
The thermostat doesn't script heating schedules. It declares a temperature and adapts continuously to maintain it. That's the upgrade.
What would it look like in your environment? Start with one goal—something measurable, something that matters, something where variance currently causes pain. Define the metric: response time, conversion rate, cycle time. Set the guardrails: budget limits, compliance rules, quality thresholds, escalation triggers. Then let the system discover tactics, continuously, within policy, adapting to reality as it shifts.
You'll notice something strange in the first week: the system will try things you wouldn't have prescribed. It will route differently, prioritize unexpectedly, allocate capacity in patterns that don't match your mental model. The metrics will improve anyway because the system optimizes for outcomes, not for conforming to your assumptions about how outcomes are achieved.
That's the moment the architecture clicks. Not automation. Not agents. Architecture that finally matches how business works.
What's next: How these concepts become a running system—component interactions, policy enforcement at scale, and what it takes to deploy Goal-Native in your environment.
"Workflows encode human limitations—what we could coordinate given bounded attention. Goal-Native encodes human intentions—the outcomes we want, with the judgment to adapt when reality shifts."
FAQ
What is Goal-Native AI?
An architecture where goals are the primary executable primitive—not tasks derived from goals, not code generated from specs. You declare outcomes (goals) and constraints (guardrails), and the system continuously discovers and adapts tactics within those boundaries. Unlike goal-driven systems that translate goals into task lists, Goal-Native executes goals directly, similar to how Kubernetes executes desired state declarations or SQL executes queries.
How is Goal-Native different from goal-oriented AI?
Goal-oriented systems use goals as reference points—generate tasks, execute, check progress, regenerate. There's a translation layer between goal and execution. Goal-Native eliminates this: the goal itself is the runtime primitive. When conditions change, there's no regeneration step; the system is already executing the goal and adapts tactics within guardrails. This removes translation latency, prevents goal-task drift, and enables continuous adaptation.
What are guardrails in Goal-Native systems?
Policy constraints defining boundaries within which the system operates freely. Unlike approval gates requiring human sign-off for each decision, guardrails are enforced automatically at runtime. Examples: "spend ≤$500 without approval," "no PII in auto-responses," "human review if customer value >$10K." Guardrails don't limit capability—they enable deployment by making the system trustworthy enough to run unsupervised.
What operations are best suited for Goal-Native?
Complex domains, as defined by the Cynefin framework, where variance is the norm: revenue operations, customer support, supply chain, quote-to-cash, incident response, procurement. The pattern: high variance, high stakes, governance required, decision volume exceeding human coordination capacity. Stable, low-variance processes with fixed compliance documentation may work better with traditional workflows.
How do humans work with Goal-Native systems?
Humans shift from the inner loop (approving transactions) to the outer loop (setting goals and guardrails). Instead of approving tickets, escalations, and exceptions, humans define what success looks like, what constraints are non-negotiable, and what policies govern edge cases. The role transforms from "approvers" to "governors"—less reactive triage, more strategic constraint architecture.
What evidence supports the Goal-Native approach?
Proven patterns: Kubernetes reconciliation loops (declarative state as executable), Model Predictive Control (continuous replanning in autonomous vehicles), cybernetics (Wiener, Ashby, Beer on goal-directed systems), emerging Spec-Driven Development in AI tooling. Industry data shows the need: Gartner reports that more than 50% of GenAI projects fail; McKinsey finds that only 39% of organizations report enterprise-level AI impact. Goal-Native addresses both the adaptability gap and the governance gap.
References
Foundational Theory:
- Wiener, N. (1948). Cybernetics: Or Control and Communication in the Animal and the Machine. MIT Press.
- Ashby, W.R. (1956). An Introduction to Cybernetics. Chapman & Hall.
- Beer, S. (1972). Brain of the Firm. Allen Lane.
- Simon, H.A. (1955). "A Behavioral Model of Rational Choice." Quarterly Journal of Economics.
- Deming, W.E. (1986). Out of the Crisis. MIT Press.
- Goldratt, E.M. (1984). The Goal: A Process of Ongoing Improvement. North River Press.
- Snowden, D.J. & Boone, M.E. (2007). "A Leader's Framework for Decision Making." Harvard Business Review.
- Meadows, D. (1999). "Leverage Points: Places to Intervene in a System." Sustainability Institute.
Industry Research:
- Gartner (2025). "The Top 10 Reasons Why GenAI Projects Fail, and How to Fix Them." Gartner Webinar
- Gartner (2025). "40% of Enterprise Applications Will Feature Task-Specific AI Agents by 2026." Gartner Newsroom
- McKinsey & Company (2025). "The State of AI: How organizations are rewiring to capture value." McKinsey
Technical Foundations:
- García, C.E., Prett, D.M., & Morari, M. (1989). "Model predictive control: Theory and practice." Automatica.
- ACL 2025 Survey. "A Modern Survey of LLM Planning Capabilities." ACL Anthology
Declarative Systems (Goal as Executable):
- Kubernetes Controllers. Kubernetes Documentation
- Kubernetes reconciliation architecture. Desired State Systems
- Jenco, B. "Desired State Systems: How declarative systems work."
- Lamport, L. "Use of Formal Methods at Amazon Web Services." AWS
- Plan-and-Act (2025). "Improving Planning of Agents for Long-Horizon Tasks." arXiv.
- Thoughts Management System (2025). "Long-horizon tasks for goal-driven LLM agents." ScienceDirect.
Agentic AI Patterns:
- GitHub (2025). "Spec-Driven Development with AI." GitHub Blog
- Ralph Loop implementations: Vercel Labs, Alibaba Cloud
- AriGraph (IJCAI 2025). "Learning Knowledge Graph World Models with Episodic Memory for LLM Agents."
- Zep (2025). "A Temporal Knowledge Graph Architecture for Agent Memory."